Slider Settings
Config Preset
The Config Preset dropdown menu displays all of your saved and imported presets at the top, with the NovelAI defaults below. Each model comes with their own variety of default presets, with the majority tuned for creative writing, and some tuned for certain writing or generation styles. The pen icon beside the dropdown is for renaming the selected preset.
The Import and Export buttons can be used to share your preset or import others people have shared, and whenever you modify one of the settings below, the Update active Preset popup will appear below the dropdown. The Update active Preset dropdown allows you to save the current preset, Reset Changes back to the presets' original settings, or save your current changes as a new preset!
Generation Options
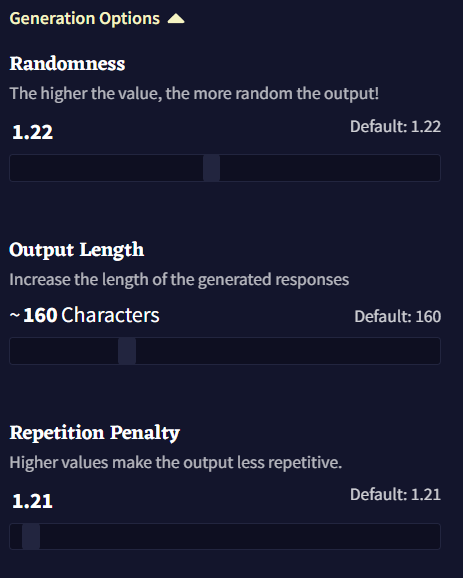
The Generation Options section of the page contains the three baseline generation settings: Randomness, Output Length, and Repetition Penalty. These settings are some of the clearest and easiest to adjust on the fly, and for the most part can be changed without having to adjust any of the Samplers below.
-
Randomness
The AI model doesn't choose tokens directly; it only gives Probabilities for tokens. More likely tokens tend to be more relevant or "correct", but if only the most likely tokens are picked, the generated text becomes repetitive and simplistic. To balance these factors, we adjust the probabilities before picking a token. Randomness and the samplers choose how much to prioritize the likely and unlikely tokens.
Randomness = 1 means token probabilities follow the typical distribution of text. It is the default setting, and the recommended choice if you don't know what to pick.
Randomness < 1 means likely tokens become even likelier and unlikely tokens become rarer. Low Randomness creates higher consistency of logical tokens, but its downside is repetitiveness and lowered creativity. When Randomness is too low, the generated text can become stuck in repetition, which is undesirable. This is an oft-discussed topic in machine learning—that picking only high-probability choices for each token creates bad output over the long run.
Randomness > 1 means the probability of generating every token becomes more equal. Higher Randomness allows more creativity, but it increases mistakes in the output, such as logical errors and grammar errors.
Keeping Randomness near 1 is the recommended practice. If Randomness is higher than 1, it is helpful to use a sampler to delete low-probability tokens.

For example, if we use the above image as our prompt and view the probabilities of the tokens to be generated after
was... Randomness 1.0
Randomness 1.0
 Randomness 1.25
Randomness 1.25
This page shows the highest-probability tokens. In the right-hand column, 1.25 Randomness has lowered the after probabilities of the tokens, with the highest tokens decreasing more. This is because high Randomness gives every token a more equal chance at being generated, and only the high probability tokens are listed on the page. The low-probability tokens, not on the page, have their after probabilities raised. High Randomness makes tokens more equal in their probabilities, but it never changes their order.
-
Output Length
The Output Length setting controls the maximum amount of text characters that the AI can generate per output, with a minimum of 4 and a maximum of 600 characters depending on your Subscription Tier.
-
Repetition Penalty
The Repetition Penalty slider decreases the probability of tokens that have appeared before in context. Higher values are stronger. Setting this slider too high will cause the AI to run out of choices and emit worse-quality tokens, while too low of a setting will allow the AI to continuously repeat words or punctuation. For example, if you wanted the AI to mention specific character names or details more often, you would lower this slider. You would increase it if you wanted it to use more varied word choices. Keep in mind that Repetition Penalty works on tokens, not words - so
intercomwill decrease the probability ofinterchange, because they share the tokeninter. ButHellowill not decrease the probability ofhello, because they are different tokens. (Repetition Penalty is equivalent toe^(Presence Penalty).)
Advanced Options
Sampling
The goal of a sampler is to maintain a diversity of tokens, but remove the lowest-probability tokens. Randomness alone is unable to accomplish this, since the low Randomness values that would remove the lowest-probability tokens would also pick only the highest-probability tokens. Samplers fill this gap. Our recommended choices for a main sampler are Unified, Min-P, or Nucleus. We have a more in-depth guide here.
-
Min-P
Min-P multiplies the most likely token's probability by this slider's value, and deletes any token underneath that number. So if the top probability is 0.6, and you choose Min-P 0.1, then token probabilities below 0.06 will be set to 0. Values near 0 are recommended when experimenting (like 0.02).
-
Mirostat
Mirostat has two sliders, Tau and Learning Rate. This sampler attempts to keep outputted tokens at a given stochasticity specified by the Tau value, with higher settings potentially leading to more creative output. The Learning Rate slider specifies how quickly Mirostat changes its estimate of stochasticity as each token is generated, with a setting of 1 being near instantaneous, and lower settings taking more tokens to change. Combining this sampler with other samplers is not recommended.
-
Nucleus
Nucleus sampling, also known as Top-P, sorts the tokens from highest to lowest probability, then adds token probabilities until their sum reaches the slider's value. The tokens outside this sum are low probability tokens, and are deleted. Deleting these low-probability tokens increases output consistency and decreases creativity. Values near 1 are recommended when experimenting (like 0.95).
-
Tail-Free
Tail-Free deletes low-probability tokens below a threshold, just like Top-P, but it calculates this threshold in a different, more complicated way. Tail, and the Tail-Free sampler are explained in detail in this blog post. Values near 1 are recommended when experimenting (like 0.95).
-
Top-A
Top-A sampling deletes every token with probability less than
(maximum token probability)^2 * A. Higher Top-A values are stricter, cutting more tokens. When the highest probability is low, then many more tokens are let through. Values near 0 are recommended when experimenting (like 0.04).
-
Top-K
With Top-K, you pick how many tokens to keep, and the rest are deleted. For example, with Top-K at 10, the sampler will keep the 10 most likely tokens, and remove the rest.
Goose Tip: Setting Top-K to 1 ensures you get the same token every time when retrying generations! The text quality won't be high, but it can be useful for testing.
-
Typical
Typical sampling is one of the more complex options available. On each output token generated, it estimates "the expected probability of a token" using an entropy calculation. If a token's probability is too high or too low compared to this expected probability, it is deleted. The Typical setting decides the proportion of tokens to keep. 1 keeps all tokens, and 0 deletes all tokens. Note that this sampler deletes high-probability tokens, which is very unusual. It will generate varied and diverse output, but of lower quality. Values near 1 are recommended when experimenting (like 0.95).
-
Unified
Unified sampling has three parameters: Linear, Quad, and Conf. Linear is equivalent to 1/Randomness, and a high value will increase the high probabilities and decrease the low probabilities. Quad shrinks low probabilities: the lower a probability is, the more it will be decreased. Conf will increase Linear when the top probabilities are all small, but it will have no effect when probabilities are concentrated in one or two tokens. The formula is
unnormalized output log-probability = (input log-probability) * (Linear + Entropy * Conf) - (input log-probability)^2 * Quad. More advice is located on this page.
- Change Samplers
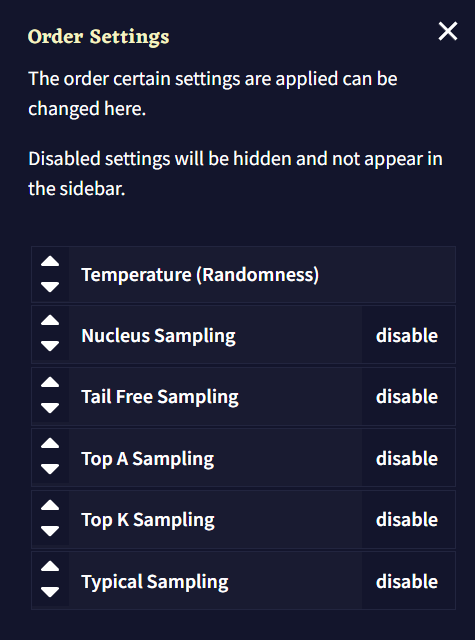
The Samplers window allows you to change the order of samplers, which are applied from top to bottom. Use the arrow buttons or drag each box individually to rearrange the sampling order, or toggle them with the buttons on the right.
The order in which you apply samplers can have unexpected and unpredictable effects. Consider starting with a default config preset and experimenting.
Repetition Penalty
The options in the Repetition penalties section, as well as the Alternative Repetition Penalty section below, are all intended to make your generations less repetitive.
-
Phrase Repetition Penalty
See the Advanced: Phrase Repetition Penalty page for more details.
-
Use Default Whitelist
See the Repetition Penalty Whitelist page for a full list of whitelisted tokens.
-
Range
Repetition Penalty Range is how many tokens, starting from the beginning of your Story Context, will have Repetition Penalty settings applied. When set to the minimum of 0 (off), repetition penalties are applied to the full range of your output, which is the same as having the slider set to the maximum of your Subscription Tier. This slider only functions when Dynamic Range is disabled.
-
Slope
The Slope slider dictates what percentage of your set Repetition Penalty and Presence penalty (which excludes Phrase Repetition Penalty) are applied to tokens. Tokens closer to the most recent token cause a greater penalty. When disabled, no sloping is applied, and all penalties apply themselves as normal.
If a token was seen among the most recent tokens, it will cause a doubled penalty value. If a token was seen at the beginning of context, it will cause zero penalty. When Slope is 1, the penalty will rise linearly between these two values. When Slope is below 1, then most tokens will cause the same penalty, with fewer of the most-recent tokens causing a doubled penalty, and fewer of the oldest tokens causing a diminished penalty. When Slope is above 1, then the more-recent half of the tokens will cause a closer-to-doubled penalty, while the older half of the tokens will cause a small penalty. For example, at Slope 10, half of context recieves 100% of your penalty values, while the other half recieves no penalties at all.
-
Dynamic Range
When enabled, Dynamic Range makes Repetition Penalty only applied to Story text. This means that penalties are not applied to Memory, Author's Note, or Lorebook text. Enabling this can allow the AI to mention lore or descriptions mentioned in those sections more often, and prevents the Range slider from being adjusted.
Alternative Repetition Penalty
-
Presence
Presence penalty is equivalent to
ln(Repetition Penalty). It applies a flat penalty if a token appears at all, and ignores how many times it appears. Note that higher values are extremely strong, since an increase of 1 will triple the strength. Repetition Penalty does the same thing and is more user-friendly; you should use that instead of Presence. A high value will result in punctuation tokens being penalized out of generating. -
Frequency
Frequency penalty applies a stacking penalty each time a token appears. This setting is dangerous and can quickly degrade outputs, so you should keep it close to 0, if it's positive at all. Small values can still have vast effects on your AI generations, cutting out too many tokens and resulting in gibberish outputs. Be wary of a high Range, which would exacerbate this problem.